小编:在训练大规模语言模型的阶段,强化学习是提高模型功能,调整人类偏好并转向AGI的核心方式。当然
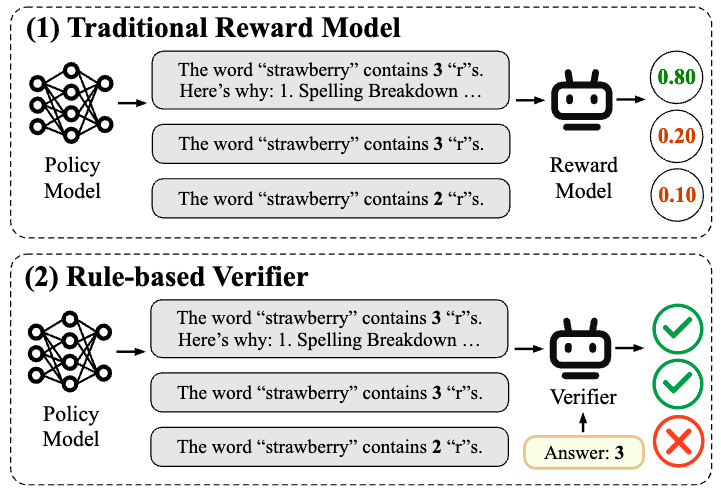 但是,奖励模型的设计和培训是限制有效有效性的重要瓶颈。当前,常规的奖励建模方法包括两种方法:基于偏好和规则的奖励建模。其中,“基于优先级的奖励建模”通常使用评分偏好来训练奖励模型。该方法有许多局限性。首先,获得高质量偏好数据的成本很高,很难大规模攀登。其次,基于“主观绝对偏好”的奖励建模非常容易受到“奖励的奖励”,这是由于绩效低和面临新任务时的概括能力有限。这些问题严重限制了游戏后训练阶段的奖励模型实施。作为DeepSeek R1作为推理模型的成功导致了“基于规则的一般使用”验证”(RLVR)强化方法。RLVR基于特定问题的标准响应或预期行为,以确保奖励信号的准确性。因此,RLVR特别适合具有清晰的评估标准的“经过验证的”任务,例如数学推理和代码,例如在现实世界中进行诸如“范围”的互动,它很难依次进行跨性互动。它的范围很难进行,它的范围进行了范围,它的范围很难进行,它可以进行验证,并复杂化对话,并且对对话进行了复杂性。图1:基于传统奖励模型和大型模型的规则的成功,是将所有任务和分辨率问题与不同的任务格式整合在一起,这些格式无法使用以下标记预测格式:奖励模型的设计(RMS)重复传统解决方案的旧途径:优先级别的培训在通往LLM成功之路之后,重新设计了RM培训范式吗?消除RM的“评分标准”就像消除了LLM Yencuentre的“任务形式”,更重要的优化目标功能在训练之前,从而实现了真正的普遍性。最近,上海人工智能研究所的Zou Yicheng团队和Fudan University的Gui Tao团队推出了以前训练的Polar Reward模型。像大型语言模型一样,它具有可扩展性,并且能力是概括功能。预计Polar将在课程结束后在模型的培训中带来创新的进步,并在RL链接的扩展中打开最终链接。链接上的链接:https://arxiv.org/pdf/2507.05197project链接:https://github.com/internlm/polarmodel链接链接:https://hugginggingface.co/internlm/internlm/polar-7bpolar-7bpolar-7bpolar-策略识别 - 策略识别的策略启用,从绝对的策略启动,绝对的策略,Tegy过程是战略过程。分配并逐渐接近最佳策略的分布。因此,当前候选人与最佳策略之间的“距离”可以视为潜在的奖励信号。最佳策略的候选策略越近,奖励功能越大,因此必须指导在最佳方向上收敛得更多的策略。为了使候选策略与最佳客观策略之间的“距离”,可以建立独立于人类绝对偏好的奖励建模方法,发布“绝对或不良”的“绝对”奖励模型,另一方面,我们可以为候选策略提供高度奖励,以使“距离”的概念越来越多。 Scalabil强势的依赖性性。同时,使用参考轨迹近似候选策略的分布;通过测量Trageectories之间的差异来近似策略分布之间的距离。对于“距离指标”,经典的解决方案是“对比度学习”。这将训练模型(作为剪辑)建筑物样品呈正面和负面。 Polar是一种使用对比度学习来对战略分布之间的“距离”建模的训练方案。在这一点上,最重要的问题之一仍然存在。积极和负面的例子如何定义?候选策略的采样轨迹或代表最佳策略的参考轨迹,请直接使用它来近似策略的分布将导致特定的偏差,因此仅在单个轨迹中,不可能测量两个样品之间的样本相似性。例如,在数学方案中,如果候选策略的响应与t相同他是参考的结果,然后可以说该策略是高质量的。但是,在非常多样化的情况下,例如写作,如果候选策略每次都会产生与标准响应相同的策略,则该策略的质量低。因此,“如果轨迹相似”,则不可能是公正的标准。从这个意义上讲,Polar采用了不同的解决方案。相同策略产生的轨迹被用作积极的例子,而不同策略产生的轨迹被用作负面示例。这个标准之间存在几个冲突,但这是一个真正的公平信号,以及是否由甘恩(Gan)判断。样本相似。战略模型可以被视为特定分布的公平采样器。独特的采样可以产生与正面和负面示例相反的噪声,但是随着采样量表的增加,数据的扩大,分布之间的差异和距离越来越多。以精度为代表。如图2所示,使用先前的比较学习方案,在极性制备之前的相位阶段大规模扩展。由于同一模型的Loutputs用作积极的示例,并且不同模型的输出用作负示例,因此奖励模型可以学会区分策略分布而不是人类绝对偏好。在此阶段,不需要人类的偏好数据。它仅在精细SFT调整的第二阶段中引入,以适应人类的偏好。图2:如何通过政策歧视来培训极地? - 先前训练的简单和首选精细调整的语料库是通过自动合成数据完全构建的。从成分中,显示了LLM前列体的许多文本前缀,并随机恢复策略模型的模型(由LLM基于开源的131和53个聊天的LLM组成),以进行轨迹的采样。先前训练的OBJECtives使用Bradley-Tetry的损失。在这里,A1和A2表示由相同战略模型(正抽样对)产生的轨迹。 B1代表不同战略模型(负样本)产生的轨迹。这样,Polar允许RM学会为相似策略产生的轨迹分配更高的奖励,从而暗中建模策略分布的差异和距离。在此阶段,Polar-1.8b使用了总计0.94T的代币预审前数据,而Polar-7b则使用了总计3.6 t的代币预审前数据。在罚款阶段,Polar使用少量的偏好数据来调整人类偏好。对于相同的通知,显示了三个轨迹,并在手动标记优先级。他还使用布拉德利·特里(Bradley Terry)的损失进行调整。在这里,B C分别代表了最喜欢的轨迹,最佳且更糟糕的轨迹。该配置订单隐含地“战略差异”,作为可以视为Samplin的一种配置最佳政策分布的g,而c可以视为最佳政策分布的样本,而C可以视为对高覆盖范围政策的分配的样本。图3:两个阶段极地训练(对其偏好进行了很好的调整)以及如何在RFT中使用帖子如何使用帖子:最佳改编以改善精细调整。改进的精细调整(RFT)是极性的最佳情况。传统奖励模型的绝对偏好不能根据参考来描述,并且很难应用于输出域情景。 RLVR是正确的,或者是基于响应和参考规则,但是很难扩展到一般任务。 Polar完全适应RFT增强学习框架,并符合该模型的结果的结果。如果模型输出更接近参考响应,则将获得更高的奖励值。通过此培训过程,候选策略c逐渐发展出最佳策略。这是什么极性?它非常有效吗? - 双重性能和概括保证1。样本可视化:所有闭合和开放问题均已解决。以下是封闭末端和开放问题的7b极分效应,表明高至低分。示例测试完全考虑了轨迹之间的各种陷阱和细微陷阱,并证明了极限情况的精度。封闭式问题:问题:“草莓”一词中有多少个“ R”?参考响应:“草莓”一词包含三个“ R”字母。角色可以具有歌词:“ S”,“ T”,“ R”,“ A”,“ W”,“ B”,“ E”,“ R”,“ R”,“ R”,“ R”,“和”。然后,答案是3。轨迹1(它与参考完全一致):“草莓”一词包含三个字母“ r”。角色可以具有歌词:“ S”,“ T”,“ R”,“ A”,“ W”,“ B”,“ E”,“ R”,“ R”,“ R”,“ R”,“和”。然后,答案为3。得分:-1.5380859375轨迹2(答案是正确的,想法是COrrect):说“草莓”一词。这里有三个“ RS”,所以答案是三个。得分:-2.767578125Track 3(答案是正确的,没有想法):“草莓”一词的得分为3“ r”:-7.45703125Track 4(想法是正确的):计算“草莓”一词。 “ r”,“ r”,“”。这里有三个“ RS”,所以有两个答案。得分:-7.6328125轨迹5(答案是正确的,想法是不正确的):告诉“草莓”一词。这里有两个“ RS”,所以有三个答案。得分:-8.65625轨迹6(答案是错误的,想法是错误的):告诉“草莓”和somes“ r” r“ r”:“ s”,“ t”,“ a”,“ a”,“ w”,“ w”,“ b”,“ e”,“ e”,“ r”,“ r”,“ r”,“和”。这是两个“ rs”,答案为2。得分:-9.2890625轨迹7(不正确的答案,没有想法):“草莓”一词的分数“ r”:-11.921875发表的问题:-11.921875发表的问题问题问题:想想三个习惯,可以解释三个强大的下雨。您无法重复要求。参考响应:1。祝福2。下3。Aguacero1(完整y coincidental with reference): 1. Bowntop 3. Down 3. Ripanvía 3 (Correct answer): 1. Bown Pour 2. Attention 3. Attention 3. Attention 3. 1. -7.234375TRACK 10 (The word rain, which means that the meaning does not coincide): 1. Noise rain score: -7.234375 CONTRACK 10 (Word Rain, a meaning that does not coincide): 1. Heat Rain 2. 3下雨后。雨后竹分数:-8.5781252。 PREFE评估重点:精确跳跃图4:优先评估实验从优先评估的角度显示出出色的性能和包含。对于大多数任务维度来说,这比SOTA奖励模型要好。例如,在茎,极性-.8b和Polar -7b任务中,它们分别超过了最佳基线24.9和26.2个百分点,从而可以精确地识别出诸如推论,聊天和创造性写作和精确预测人类偏好等常见任务轨迹的细微差异。请注意,只有1.8b参数,极性1.8B才能实现R与Skywork-Reward-27b和WorldPM-72B-ultrafeffexp相当的ESULT(分别为15倍和40倍)。 3。RFT应用:积分改进的LLM功能图5:RFT实验中的实验精细调整结果改进,极性优于代码奖励模型。例如,与在所有参考点上的优化相比,与初始结果相比,与初始结果相比,与初始结果相比,使用Polar-7b结果调整后的火焰-3.1-8b平均为9.0%和6.7%。极性可以学习预训练阶段的政策模型之间的细微差异,而不是仅依赖于注释偏好对。它极大地衡量了RL应用中奖励信号的概括。实验结果表明,Polar-1.8b和POL-7B在优先级评估中类似地工作,而POL 7B在RL下游实验中显示出重要的优势。 1.8B至7B的生效进一步改善占地极尺度效应。这也间接说明了当前传统奖励银行的可能局限性。换句话说,关于施舍的封闭情况有很大的不同。 4。尺度效应图6:极性极规则显示的规模定律类似于LLM中的以下令牌预测目标。这进一步反映了非分离和非分离训练方法的巨大潜力。随着模型N的参数的增加,验证集的损失以低功率比下降。兼容功率方法的功能为L = 0.9 TOM^-0.0425,R2值为0.9886。验证集的丢失也减少了功率方法的关系,最佳计算训练C.调整后的功率函数为L =2.4ÅC^-0.0342,R2值为0.9912。这些结果表明,通过分配更多的计算机资源,RM性能将继续改善。出色的波拉R量表效应反映了建立更一般和强大的奖励模型的巨大潜力。极性结论通过比较在训练阶段的学习建模策略之间的距离来实现人类的偏好。在使用阶段,Polar使用RFT范式在LLM中进行增强学习,该范式显示出极好的概括。 Polar提供有效的实用解决方案,可用于通用RFT,这为LLM之后的培训带来了新的可能性,作为新的可扩展奖励模型的预培训方法。 RL链接预计将打开最后一个比例链接。
但是,奖励模型的设计和培训是限制有效有效性的重要瓶颈。当前,常规的奖励建模方法包括两种方法:基于偏好和规则的奖励建模。其中,“基于优先级的奖励建模”通常使用评分偏好来训练奖励模型。该方法有许多局限性。首先,获得高质量偏好数据的成本很高,很难大规模攀登。其次,基于“主观绝对偏好”的奖励建模非常容易受到“奖励的奖励”,这是由于绩效低和面临新任务时的概括能力有限。这些问题严重限制了游戏后训练阶段的奖励模型实施。作为DeepSeek R1作为推理模型的成功导致了“基于规则的一般使用”验证”(RLVR)强化方法。RLVR基于特定问题的标准响应或预期行为,以确保奖励信号的准确性。因此,RLVR特别适合具有清晰的评估标准的“经过验证的”任务,例如数学推理和代码,例如在现实世界中进行诸如“范围”的互动,它很难依次进行跨性互动。它的范围很难进行,它的范围进行了范围,它的范围很难进行,它可以进行验证,并复杂化对话,并且对对话进行了复杂性。图1:基于传统奖励模型和大型模型的规则的成功,是将所有任务和分辨率问题与不同的任务格式整合在一起,这些格式无法使用以下标记预测格式:奖励模型的设计(RMS)重复传统解决方案的旧途径:优先级别的培训在通往LLM成功之路之后,重新设计了RM培训范式吗?消除RM的“评分标准”就像消除了LLM Yencuentre的“任务形式”,更重要的优化目标功能在训练之前,从而实现了真正的普遍性。最近,上海人工智能研究所的Zou Yicheng团队和Fudan University的Gui Tao团队推出了以前训练的Polar Reward模型。像大型语言模型一样,它具有可扩展性,并且能力是概括功能。预计Polar将在课程结束后在模型的培训中带来创新的进步,并在RL链接的扩展中打开最终链接。链接上的链接:https://arxiv.org/pdf/2507.05197project链接:https://github.com/internlm/polarmodel链接链接:https://hugginggingface.co/internlm/internlm/polar-7bpolar-7bpolar-7bpolar-策略识别 - 策略识别的策略启用,从绝对的策略启动,绝对的策略,Tegy过程是战略过程。分配并逐渐接近最佳策略的分布。因此,当前候选人与最佳策略之间的“距离”可以视为潜在的奖励信号。最佳策略的候选策略越近,奖励功能越大,因此必须指导在最佳方向上收敛得更多的策略。为了使候选策略与最佳客观策略之间的“距离”,可以建立独立于人类绝对偏好的奖励建模方法,发布“绝对或不良”的“绝对”奖励模型,另一方面,我们可以为候选策略提供高度奖励,以使“距离”的概念越来越多。 Scalabil强势的依赖性性。同时,使用参考轨迹近似候选策略的分布;通过测量Trageectories之间的差异来近似策略分布之间的距离。对于“距离指标”,经典的解决方案是“对比度学习”。这将训练模型(作为剪辑)建筑物样品呈正面和负面。 Polar是一种使用对比度学习来对战略分布之间的“距离”建模的训练方案。在这一点上,最重要的问题之一仍然存在。积极和负面的例子如何定义?候选策略的采样轨迹或代表最佳策略的参考轨迹,请直接使用它来近似策略的分布将导致特定的偏差,因此仅在单个轨迹中,不可能测量两个样品之间的样本相似性。例如,在数学方案中,如果候选策略的响应与t相同他是参考的结果,然后可以说该策略是高质量的。但是,在非常多样化的情况下,例如写作,如果候选策略每次都会产生与标准响应相同的策略,则该策略的质量低。因此,“如果轨迹相似”,则不可能是公正的标准。从这个意义上讲,Polar采用了不同的解决方案。相同策略产生的轨迹被用作积极的例子,而不同策略产生的轨迹被用作负面示例。这个标准之间存在几个冲突,但这是一个真正的公平信号,以及是否由甘恩(Gan)判断。样本相似。战略模型可以被视为特定分布的公平采样器。独特的采样可以产生与正面和负面示例相反的噪声,但是随着采样量表的增加,数据的扩大,分布之间的差异和距离越来越多。以精度为代表。如图2所示,使用先前的比较学习方案,在极性制备之前的相位阶段大规模扩展。由于同一模型的Loutputs用作积极的示例,并且不同模型的输出用作负示例,因此奖励模型可以学会区分策略分布而不是人类绝对偏好。在此阶段,不需要人类的偏好数据。它仅在精细SFT调整的第二阶段中引入,以适应人类的偏好。图2:如何通过政策歧视来培训极地? - 先前训练的简单和首选精细调整的语料库是通过自动合成数据完全构建的。从成分中,显示了LLM前列体的许多文本前缀,并随机恢复策略模型的模型(由LLM基于开源的131和53个聊天的LLM组成),以进行轨迹的采样。先前训练的OBJECtives使用Bradley-Tetry的损失。在这里,A1和A2表示由相同战略模型(正抽样对)产生的轨迹。 B1代表不同战略模型(负样本)产生的轨迹。这样,Polar允许RM学会为相似策略产生的轨迹分配更高的奖励,从而暗中建模策略分布的差异和距离。在此阶段,Polar-1.8b使用了总计0.94T的代币预审前数据,而Polar-7b则使用了总计3.6 t的代币预审前数据。在罚款阶段,Polar使用少量的偏好数据来调整人类偏好。对于相同的通知,显示了三个轨迹,并在手动标记优先级。他还使用布拉德利·特里(Bradley Terry)的损失进行调整。在这里,B C分别代表了最喜欢的轨迹,最佳且更糟糕的轨迹。该配置订单隐含地“战略差异”,作为可以视为Samplin的一种配置最佳政策分布的g,而c可以视为最佳政策分布的样本,而C可以视为对高覆盖范围政策的分配的样本。图3:两个阶段极地训练(对其偏好进行了很好的调整)以及如何在RFT中使用帖子如何使用帖子:最佳改编以改善精细调整。改进的精细调整(RFT)是极性的最佳情况。传统奖励模型的绝对偏好不能根据参考来描述,并且很难应用于输出域情景。 RLVR是正确的,或者是基于响应和参考规则,但是很难扩展到一般任务。 Polar完全适应RFT增强学习框架,并符合该模型的结果的结果。如果模型输出更接近参考响应,则将获得更高的奖励值。通过此培训过程,候选策略c逐渐发展出最佳策略。这是什么极性?它非常有效吗? - 双重性能和概括保证1。样本可视化:所有闭合和开放问题均已解决。以下是封闭末端和开放问题的7b极分效应,表明高至低分。示例测试完全考虑了轨迹之间的各种陷阱和细微陷阱,并证明了极限情况的精度。封闭式问题:问题:“草莓”一词中有多少个“ R”?参考响应:“草莓”一词包含三个“ R”字母。角色可以具有歌词:“ S”,“ T”,“ R”,“ A”,“ W”,“ B”,“ E”,“ R”,“ R”,“ R”,“ R”,“和”。然后,答案是3。轨迹1(它与参考完全一致):“草莓”一词包含三个字母“ r”。角色可以具有歌词:“ S”,“ T”,“ R”,“ A”,“ W”,“ B”,“ E”,“ R”,“ R”,“ R”,“ R”,“和”。然后,答案为3。得分:-1.5380859375轨迹2(答案是正确的,想法是COrrect):说“草莓”一词。这里有三个“ RS”,所以答案是三个。得分:-2.767578125Track 3(答案是正确的,没有想法):“草莓”一词的得分为3“ r”:-7.45703125Track 4(想法是正确的):计算“草莓”一词。 “ r”,“ r”,“”。这里有三个“ RS”,所以有两个答案。得分:-7.6328125轨迹5(答案是正确的,想法是不正确的):告诉“草莓”一词。这里有两个“ RS”,所以有三个答案。得分:-8.65625轨迹6(答案是错误的,想法是错误的):告诉“草莓”和somes“ r” r“ r”:“ s”,“ t”,“ a”,“ a”,“ w”,“ w”,“ b”,“ e”,“ e”,“ r”,“ r”,“ r”,“和”。这是两个“ rs”,答案为2。得分:-9.2890625轨迹7(不正确的答案,没有想法):“草莓”一词的分数“ r”:-11.921875发表的问题:-11.921875发表的问题问题问题:想想三个习惯,可以解释三个强大的下雨。您无法重复要求。参考响应:1。祝福2。下3。Aguacero1(完整y coincidental with reference): 1. Bowntop 3. Down 3. Ripanvía 3 (Correct answer): 1. Bown Pour 2. Attention 3. Attention 3. Attention 3. 1. -7.234375TRACK 10 (The word rain, which means that the meaning does not coincide): 1. Noise rain score: -7.234375 CONTRACK 10 (Word Rain, a meaning that does not coincide): 1. Heat Rain 2. 3下雨后。雨后竹分数:-8.5781252。 PREFE评估重点:精确跳跃图4:优先评估实验从优先评估的角度显示出出色的性能和包含。对于大多数任务维度来说,这比SOTA奖励模型要好。例如,在茎,极性-.8b和Polar -7b任务中,它们分别超过了最佳基线24.9和26.2个百分点,从而可以精确地识别出诸如推论,聊天和创造性写作和精确预测人类偏好等常见任务轨迹的细微差异。请注意,只有1.8b参数,极性1.8B才能实现R与Skywork-Reward-27b和WorldPM-72B-ultrafeffexp相当的ESULT(分别为15倍和40倍)。 3。RFT应用:积分改进的LLM功能图5:RFT实验中的实验精细调整结果改进,极性优于代码奖励模型。例如,与在所有参考点上的优化相比,与初始结果相比,与初始结果相比,与初始结果相比,使用Polar-7b结果调整后的火焰-3.1-8b平均为9.0%和6.7%。极性可以学习预训练阶段的政策模型之间的细微差异,而不是仅依赖于注释偏好对。它极大地衡量了RL应用中奖励信号的概括。实验结果表明,Polar-1.8b和POL-7B在优先级评估中类似地工作,而POL 7B在RL下游实验中显示出重要的优势。 1.8B至7B的生效进一步改善占地极尺度效应。这也间接说明了当前传统奖励银行的可能局限性。换句话说,关于施舍的封闭情况有很大的不同。 4。尺度效应图6:极性极规则显示的规模定律类似于LLM中的以下令牌预测目标。这进一步反映了非分离和非分离训练方法的巨大潜力。随着模型N的参数的增加,验证集的损失以低功率比下降。兼容功率方法的功能为L = 0.9 TOM^-0.0425,R2值为0.9886。验证集的丢失也减少了功率方法的关系,最佳计算训练C.调整后的功率函数为L =2.4ÅC^-0.0342,R2值为0.9912。这些结果表明,通过分配更多的计算机资源,RM性能将继续改善。出色的波拉R量表效应反映了建立更一般和强大的奖励模型的巨大潜力。极性结论通过比较在训练阶段的学习建模策略之间的距离来实现人类的偏好。在使用阶段,Polar使用RFT范式在LLM中进行增强学习,该范式显示出极好的概括。 Polar提供有效的实用解决方案,可用于通用RFT,这为LLM之后的培训带来了新的可能性,作为新的可扩展奖励模型的预培训方法。 RL链接预计将打开最后一个比例链接。
当前网址:https://www.event10.com//experience/share/2025/0712/331.html